我自從寫了 介紹好用工具:Ollama 快速在本地啟動並執行大型語言模型 文章後,就幾乎都在本機用 Ollama 執行各種大語言模型的推論。由於幾天前 TAIDE 團隊發表了一套符合台灣語言和文化特性的大語言模型(TAIDE-LX-7B),我當下就立刻用 Ollama 跑起來了。這篇文章我將分享幾個簡單的小步驟,幫助大家也可以很順利的在本機將 TAIDE-LX-7B-Chat-4bit 模型跑起來。

理論上,任何一套 GGUF 格式的大語言模型檔案,都可以透過 Ollama 來執行。而 TAIDE 團隊提供的 TAIDE-LX-7B-Chat-4bit 模型以 LaMA2-7b 為基礎,這個版本是 4bit 的量化版本,因此要建立成 Ollama 可以使用的模型就相當簡單,以下是操作步驟:
-
下載 taide-7b-a.2-q4_k_m.gguf 檔案
你要先進入 Hugging Face 的 taide/TAIDE-LX-7B-Chat-4bit 頁面,然後必須先同意授權條款才能下載與使用此模型。
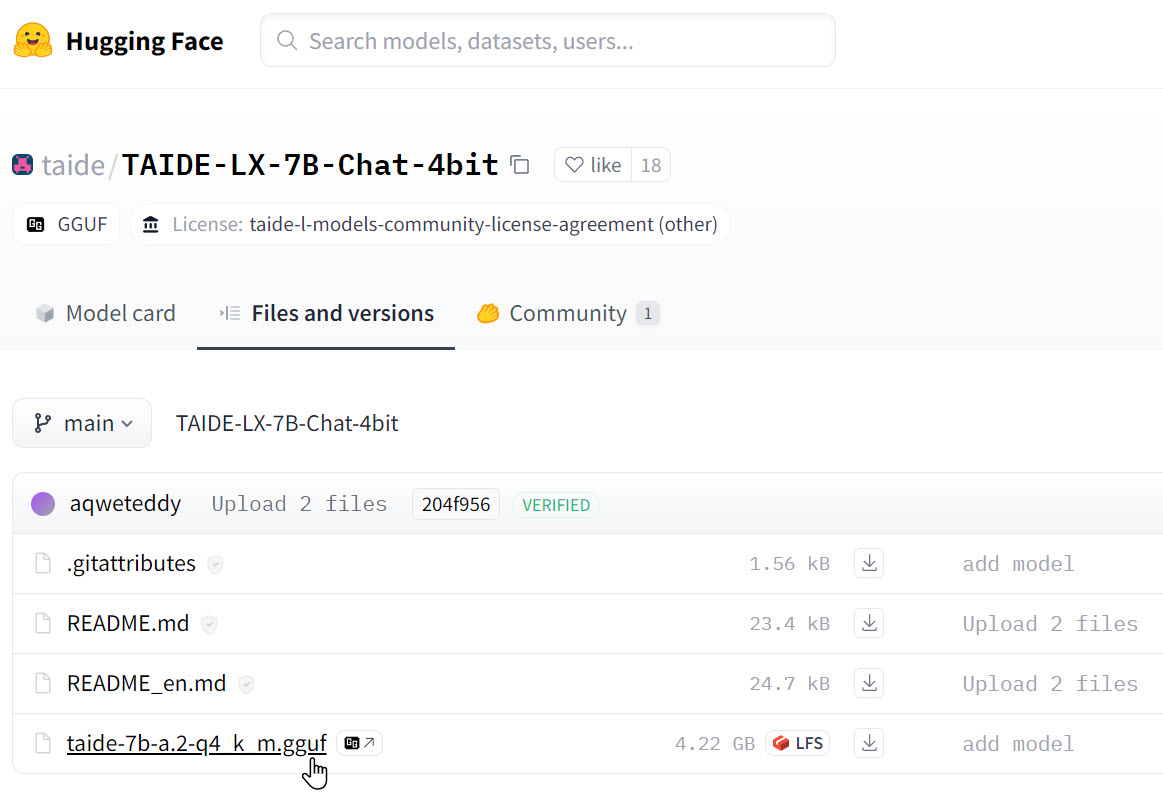
切換到 Files and versions 頁籤,下載 taide-7b-a.2-q4_k_m.gguf 檔案 (4.22 GB)
-
在本機建立一個 Modelfile 模型定義檔
這是一個文字檔,檔案內容如下:
FROM ./taide-7b-a.2-q4_k_m.gguf
-
建立 Ollama 模型
ollama create taide-lx-7b-chat-4bit:latest -f Modelfile
-
執行 Ollama 模型
ollama run taide-lx-7b-chat-4bit:latest
更完整的 Ollama 用法,建議參考我的介紹好用工具:Ollama 快速在本地啟動並執行大型語言模型文章。
相關連結